Original text (24th January)
This page is explicitly “noindex,follow”.
Here are some links to pages that (at the time of writing) are not and have never been linked to anywhere else:
- Here’s a link to a page that is blocked in robots.txt.
- Here’s a nofollowed link.
- Here’s a perfectly normal link.
In about a month I’ll remove that robots.txt rule, and see if Google crawls the previously blocked page. If it does, that means that this page is still being treated as “noindex,follow”. If it doesn’t, and that remains the case for a reasonable period of time, that indicates that this page is being treated as “noindex,nofollow”.
I’m using robots.txt to do this because it means I don’t have to update this page to change what it (follow) links to – so if this mechanic described by John Mueller refreshes when the page is updated, that won’t invalidate my methodology.
Here’s a link to the Screaming Frog output as it currently stands.
Update (29th January)
Here’s the site: search result on January 29th (I forgot to check sooner):
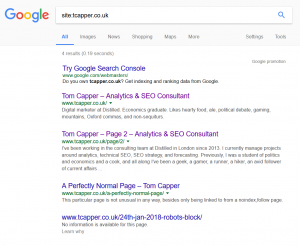
This is behaving as expected, with two of the pages linked to from here both found, but not the one that I’ve linked to with a “nofollow” attribute.
In addition, I decided to add this link, in case I need a 2nd robots.txt blocked URL to play with later:
- Here’s a second link to a page that is blocked in robots.txt (just in case).